GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks
本文最后更新于 2024年8月5日 下午
GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks
论文要做什么
通过LLM(大语言模型)与GM(图模型)相结合,实现一个既能解决预定义任务又能解决开放式任务的模型。
实验结果表明,该方法在零样本分类等任务中表现出色,并具有广泛的应用前景。
论文背景
现有将LLM应用到GM的工作主要有两种
- 将LLM作为Enhancer(增强器)
- 弊端:不能处理开放式任务
- 将LLM作为Predictor(预测器)
- 弊端:容易出现幻觉答案
作者通过GraphTranslator模型对齐GM和LLM,来扩展GM处理开放式任务的能力。
论文结果
通过现实数据集评估了GraphTranslator,结果表明了GraphTranslator在零样本分类任务和图问答任务上的有效性。
论文方法
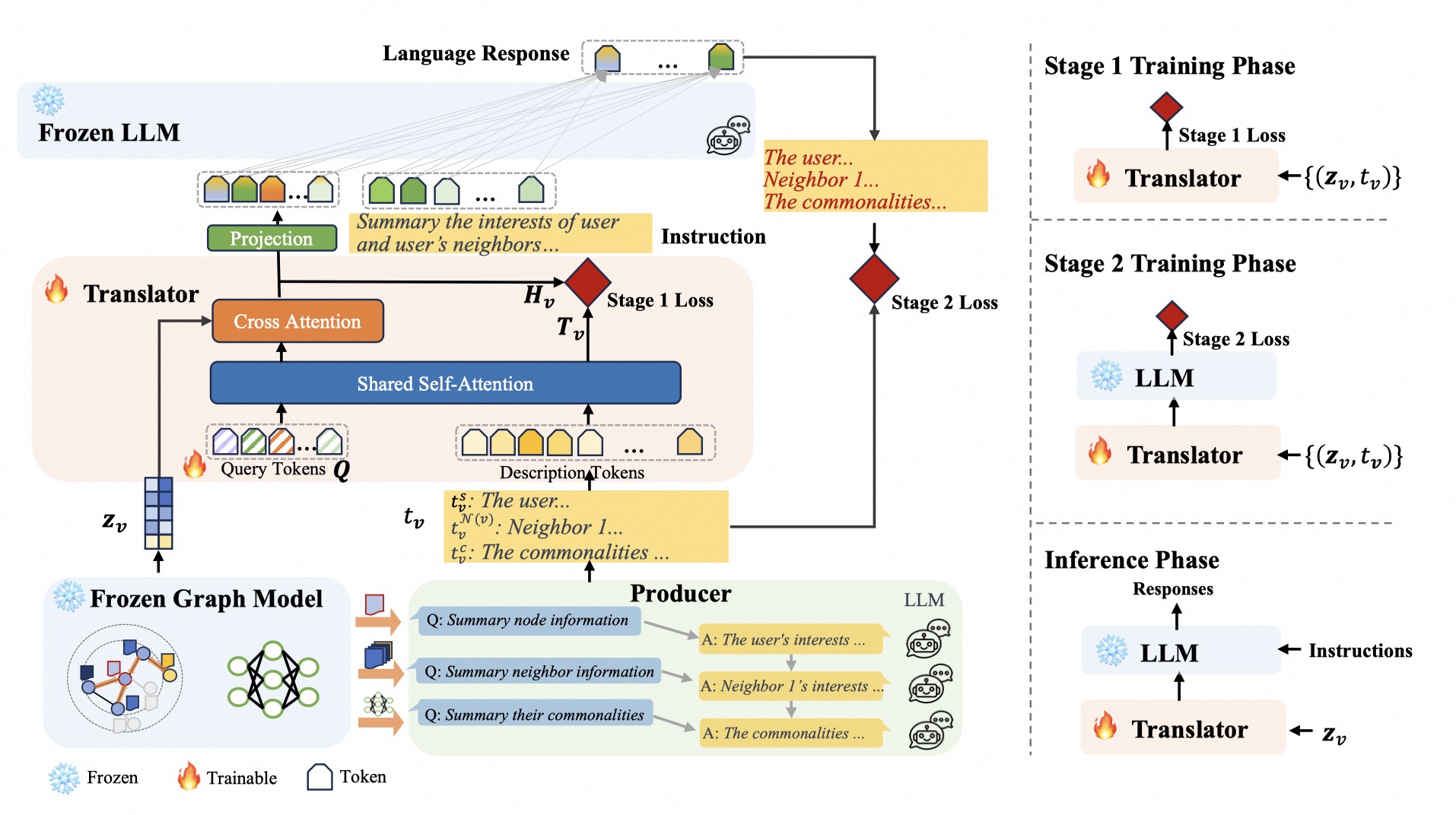
上图左半部分可以看到论文的方法包括四个模块:冻结的GM,冻结的LLM,Producer和Translator。
【Whalepaper第100期】NLP论文研读:GraphTranslator-结合预训练的图模型与大型语言模型来处理预定义和开放式任务【精准空降到 12:46】
1. 冻结的GM
- 冻结的GM主要作用:为数据集的所有节点生成嵌入向量\(z_v\)
- \(z_v\)会传给Producer和Translator的交叉注意力层(Cross Attention)
- 给定一个图\(\mathcal G = (\mathcal V, A,
\{s_v\}_{v \in \mathcal V}), A\in \{0,1\}^{N\times N}\)
- \(\mathcal V\)是所有节点,\(A\)是图的邻接矩阵,\(s_v\)是节点\(v\)的文本描述
- 典型的图神经网络表示为\(\mathcal
g_\theta(A,X)\)
- \(\theta\)是可学习的参数,\(X\)是通过词袋(BoW)处理\(\left\{s_v\right\}\)得到的embedding,\(\mathcal g\)使用的是GraphSAGE
- GraphSAGE在目标节点\(v\)周围采样固定大小(2跳)的邻居\(\mathcal N(v)\),构成节点\(v\)的子图,然后将节点对上一层嵌入\(h_v^{k-1}\)与聚合的领域向量\(\left\{h_u^{k-1},\forall u\in \mathcal
N(v)\right\}\)连接起来。(将邻居的当前embedding聚合起来,然后与目标节点的embedding拼接起来,逐层传播聚合,最后可以得到\(z_v\))
- \(h_v^k = \sigma\left(W^k \cdot
CONCAT\left(h_v^{k-1} \cup AGGREGATE_k\left\{h_u^{k-1},\forall u \in
\mathcal N(v)\right\}\right)\right)\)
- \(W^k\)是\(\mathcal g\)的一个参数,表示第\(k\)层的权重矩阵
- \(z_v = \mathcal g_{\theta^*}\left(A,
X\right)_v\)
- 这里的\(\theta ^*\)表示参数是固定的,所以这个模块是冻结的GM。(作者说GraphSAGE是阿里已上线的参数,没有改过)
- \(h_v^k = \sigma\left(W^k \cdot
CONCAT\left(h_v^{k-1} \cup AGGREGATE_k\left\{h_u^{k-1},\forall u \in
\mathcal N(v)\right\}\right)\right)\)
2. Producer
作用利用LLM生成节点嵌入和文本描述的匹配数据,并文本化节点信息。对齐GM和LLM
- 生成一个节点文本对
node_id embedding paper_summary citepapers_summary title 42 -0.077210054, 0.26279667, 0.82795596, ... This paper studies ... These papers cover ... contact representations of sparse planar graphs
构建对齐数据\(P=\left\{(z_v,t_v)\right\}_{i=1}^{\mathcal N_p}\)
- \(t_v = \left\{t_v^s,t_v^{\mathcal
N(v)},t_v^c\right\}\),从左到右分别是:自己的属性信息,邻居的属性信息,节点间的共性
- 实际代码中发现只有前两个,第三个在代码和附录的prompt中均未找到
- \(t_v\)是使用"Chain of
Thought"(CoT)引导GPT生成的高质量描述

- \(t_v^s\): 通常节点属性(文本或数字数据)被视为每个节点的特征,使用词袋模型实现。Producer使用LLM总结并分析训练集中每个节点\(v\)的属性,得到节点描述记为\(t_v^s\)
- \(t_v^{\mathcal N(v)}\): GraphSAGE随机抽样邻居节点\(\mathcal N(v)\)的子集并聚合他们的表示,得到neighbor embedding。节点和邻居信息通过加权求和或进一步融合。Producer使用LLM总结\(\mathcal N(v)\)的属性,得到邻居信息的描述记为\(t_v^{\mathcal N(v)}\)
- \(z_v\)也就是上表中的embedding,实现代码位于producer.py的133行

- \(t_v = \left\{t_v^s,t_v^{\mathcal
N(v)},t_v^c\right\}\),从左到右分别是:自己的属性信息,邻居的属性信息,节点间的共性
具体的代码位于producer.py的
LLM.inference_chatglm_arxiv
3. Translator
作用:将节点嵌入转化为token,实现GM和LLM对齐
执行流程:
从上边流程图可知,输入包括
Query Token \(Q\)
\(Q\)是需要学习的参数,所以开始时赋值为0
1
2
3
4
5
6
7
8
9
10# Translator/models/translator_models/translator.py init_Qformer
query_tokens = nn.Parameter(
torch.zeros(1, num_query_token, encoder_config.hidden_size)
)
query_tokens.data.normal_(mean=0.0, std=encoder_config.initializer_range)
# Translator/models/translator_models/translator_qformer_arxiv.py TranslatorQformerArxiv.forward
# 这里的behavior_embeds是z_v
# 将Q的形状扩展为z_v的形状
query_tokens = self.query_tokens.expand(behavior_embeds.shape[0], -1, -1)在第一次训练阶段的第一步就是训练\(Q\)进行学习
Description Tokens \(t_v\)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# Translator/models/translator_models/translator_qformer_arxiv.py
def init_tokenizer(cls):
tokenizer = BertTokenizer.from_pretrained("../models/bert-base-uncased")
tokenizer.add_special_tokens({"bos_token": "[DEC]"})
return tokenizer
# Translator/models/translator_models/translator_qformer_arxiv.py TranslatorQformerArxiv.__init__
self.tokenizer = self.init_tokenizer()
# Translator/models/translator_models/translator_qformer_arxiv.py TranslatorQformerArxiv.forward
text_tokens = self.tokenizer(
text, # 这里的text是上边表格中一条数据的`paper_summary`
padding="max_length",
truncation=True,
max_length=self.max_txt_len,
return_tensors="pt",
).to(behavior_embeds.device)Node Embedding \(z_v\)
在Producer模块存到了数据中,对应上表的
embedding1
behavior_embeds = torch.unsqueeze(samples[1], dim=1)
Translator中包括两个编码器\(f_t(\cdot)\)和\(f_z(\cdot)\)
- \(f_t(\cdot)\)基于BERT实现,用于提取语言特征\(T_v = f_t(t_v)\)
- \(f_t(\cdot)\)包含12层Transformer块
- \(f_z(\cdot)\)基于Transformer网络
- 以M个可学习的token embeddings作为输入,称为query token \(Q=\{q_i\}_{i=1}^M\)
- 输出M个特征\(H_v=f_z(Q,z_v)=\{h_{v,i}\}_{i=1}^M\),提取\(z_v\)中与\(t_v\)最相关的信息
- 使用自注意力层相互交互,通过交叉注意力层(Cross Attention)与节点嵌入\(z_v\)交互,并通过在\(f_t\)和\(f_z\)之间共享的自注意力层(Shared Self-Attention)与\(t_v\)通信
- \(f_t(\cdot)\)基于BERT实现,用于提取语言特征\(T_v = f_t(t_v)\)
损失值将由\(T_v\)和\(H_v\)计算得出,具体在下面训练部分说明
4.Train
训练分为了两个阶段
- Train-1: 对齐GM和Text
- Train-2: 对齐GM和LLM
Train1
对齐GM和Text,也就是对齐\(H_v=\{h_{v,
i}\}_{i=1}^M\)和\(\tilde
t_v\)(\(\tilde t _v\)是\(T_v\)的[CLS]token嵌入)
对应的代码为
根据作者的注释可以将forward函数分为4个部分(第一部分姑且命名为Text Feature Extractor)
Text
Feature
Extractor
这部分为论文中提到的\(f_t\),
使用Qformer.bert处理text_tokens(\(t_v\))得到text_feat(\(T_v\)).
behavior_feats表示\(H_v = f_z(Q, z_v) = \left\{h_{v, i}\right\}_{i=1}^M\), M指可学习的token embedding的数量即num_query_tokens对于节点嵌入\(z_v\) ,我们还采用基于 Transformer 的网络\(f_z(\cdot)\) ,以\(M\)个可学习的标记嵌入作为输入(称为查询标记\(Q=\left\{q_i\right\}_{i=1}^M\),输出\(𝑀\)特征\(H_v=\left\{h_{v,i}\right\}_{𝑖=1}^𝑀\)和\(H_v=f_z(Q,z_v)\) ,提取与\(𝑡_𝑣\)最相关的\(z_𝑣\)信息。
self.tokenizer在初始化中使用tokenizer.add_special_tokens({"bos_token": "[DEC]"})实现了将[CLS]标签替换为[DEC]- BERT模型的默认输入格式为
[CLS] xxxxx [SEP],文本数据的开头通常会有[CLS]标签
- BERT模型的默认输入格式为
使用bert提取\(t_v\)的特征得到\(T_v\)
对于文本描述\(t_v\) ,我们利用文本编码器\(f_t(\cdot)\)(例如 BERT [4] )提取语言特征\(T_v = f_t(t_v)\),其中\(f_t(\cdot)\)包含 12 层 Transformer 块。
1 | |
Image-text
Contrastive
这里感觉应该是Graph-text Contrastive,不知道是不是作者打错了
通过计算 \(h_{v,i}\)和\(T_v\)的最相似的索引 与 \(\tilde t_v\)和\(H_v\)的最相似的索引 的交叉熵损失的均值
loss_itc\(\tilde t_v\)是\(T_v\)的
[CLS]token embedding对比目标通过最大化它们的相互信息来对齐\(H_v\)和\(\tilde t_v\)。我们首先计算\(\tilde t_v\)与\(H_v\)中每个token之间的成对相似度,并选择最高的一个作为相似度得分,
然后将正对的相似度与负对的相似度进行对比。
1 | |
Image-text
Matching
这里是计算正对相似度和负对相似度进行对比
分别计算了text的负样本graph(不是这个text对应的图节点) 和 计算了graph的负样本text(不是这个graph对应的text)
使用每个graph的负样本text的id(
text_ids_all)作为BERT输入,对比目标通过最大化它们的相互信息来对齐\(H_v\)和\(\tilde t_v\)。我们首先计算\(\tilde t_v\)与\(H_v\)中每个token之间的成对相似度,并选择最高的一个作为相似度得分,然后将正对的相似度与负对的相似度进行对比。
1 | |
Image
Captioning
标题的意思应该是基于给定的graph生成描述文本,Q-Former生成文本后会得到一个损失值
论文中没有找到对应的出处,GPT回答是“指导模型在训练过程中生成更高质量的文本”
1 | |
Final
- 模型的损失使用前面三个阶段的损失和
1 | |
Train2
这一阶段的主要目标是训练Translator实现GM-LLM对齐
实现的代码主要位于Translator/models/translator_models/translator_chatglm_arxiv.py
训练过程中重新使用Producer的结果作为数据集,没有直接存储stage1的\(H_v\)使用
这里的\(H_v\)(
vtokens)被一个线性层self.chatglm2_proj映射为LLM相同的维度上prepare_lm_input的主要返回三个参数input_ids,labels,inputs_embedsinput_ids = a_ids + b_idsa_ids = [IMAGE_TOKEN_ID] * nvtoken + tokenizer.encode(text, add_special_tokens=False),IMAGE_TOKEN_ID是固定参数101,nvtoken是\(H_v\)的特征数,text是论文流程图中的Instructionb_ids = tokenizer.encode(ans, add_special_tokens=False),ans是\(t_v\)中的一段input_ids = [IMAGE_TOKEN_ID]*nvtoken + 'Question: Please summarize the topic and content of the paper and its citations in English. Answer:' + 'This paper studies ...'文本在程序中均为embedding
label = input_ids.detach().clone(),label[:context_length]=-100label会复制input_ids, 然后将a_ids的位置改为-100, 用于计算损失时忽略
inputs_embeds=self.chatglm2_model.transformer.embedding.word_embeddings(input_ids)- 将
input_ids通过LLM的嵌入层转换为嵌入向量 - 将
vtoken(\(H_v\))插入到相应位置的嵌入向量中,inputs_embeds[:, nvtoken_id: nvtoken_id + nvtoken] = vtokens - 最后将嵌入向量的形状调整为适合LLM输入的格式,
inputs_embeds = inputs_embeds.transpose(0, 1).contiguous()
- 将
1 | |